协程、延迟函数调用、以及恐慌和恢复
此篇文章将介绍协程和延迟函数调用。协程和延迟函数调用是Go中比较独特的两个特性。 恐慌和恢复也将在此篇文章中得到简单介绍。本文并非全面地对这些特性进行介绍,后面的其它文章会陆续补全本文的未介绍的内容。
协程(goroutine)
现代CPU一般含有多个核,并且一个核可能支持多线程。换句话说,现代CPU可以同时执行多条指令流水线。 为了将CPU的能力发挥到极致,我们常常需要使我们的程序支持并发(concurrent)计算。
并发计算是指若干计算可能在某些时间片段内同时运行的情形。 下面这两张图描绘了两种并发计算的场景。在此图中,A和B表示两个计算。 在第一种情形中,两个计算只在某些时间片段同时运行。 第二种情形称为并行(parallel)计算。在并行计算中,多个计算在任何时间点都在同时运行。并行计算属于特殊的并发计算。
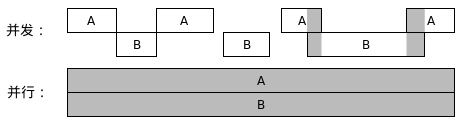
并发计算可能发生在同一个程序中、同一台电脑上、或者同一个网络中。 在《Go语言101》中,我们只谈及发生在同一个程序中的并发计算。 在Go编程中,协程是创建计算的唯一途径。
协程有时也被称为绿色线程。绿色线程是由程序的运行时(runtime)维护的线程。一个绿色线程的内存开销和情景转换(context switching)时耗比一个系统线程常常小得多。 只要内存充足,一个程序可以轻松支持上万个并发协程。
Go不支持创建系统线程,所以协程是一个Go程序内部唯一的并发实现方式。
每个Go程序启动的时候只有一个对用户可见的协程,我们称之为主协程。
一个协程可以开启更多其它新的协程。在Go中,开启一个新的协程是非常简单的。
我们只需在一个函数调用之前使用一个go关键字,即可让此函数调用运行在一个新的协程之中。
当此函数调用退出后,这个新的协程也随之结束了。我们可以称此函数调用为一个协程调用(或者为此协程的启动调用)。
一个协程调用的所有返回值(如果存在的话)必须被全部舍弃。
time.Duration是一个在time标准库包中定义的类型。
此类型的底层类型为内置类型int64。
底层类型这个概念将在下一篇文章中介绍。
package main
import (
"log"
"math/rand"
"time"
)
func SayGreetings(greeting string, times int) {
for i := 0; i < times; i++ {
log.Println(greeting)
d := time.Second * time.Duration(rand.Intn(5)) / 2
time.Sleep(d) // 睡眠片刻(随机0到2.5秒)
}
}
func main() {
rand.Seed(time.Now().UnixNano()) // Go 1.20之前需要
log.SetFlags(0)
go SayGreetings("hi!", 10)
go SayGreetings("hello!", 10)
time.Sleep(2 * time.Second)
}
hi!
hello!
hello!
hello!
hello!
hi!
当一个程序的主协程退出后,此程序也就退出了,即使还有一些其它协程在运行。
和前面的几篇文章不同,上面的例子程序使用了log标准库而不是fmt标准库中的Println函数。
原因是log标准库中的打印函数是经过了同步处理的(下一节将解释什么是并发同步),而fmt标准库中的打印函数却没有被同步。
如果我们在上例中使用fmt标准库中的Println函数,则不同协程的打印可能会交织在一起。(虽然对此例来说,交织的概率很低。)
并发同步(concurrency synchronization)
- 在一个计算向一段内存写数据的时候,另一个计算从此内存段读数据,结果导致读出的数据的完整性得不到保证。
- 在一个计算向一段内存写数据的时候,另一个计算也向此段内存写数据,结果导致被写入的数据的完整性得不到保证。
这些情形被称为数据竞争(data race)。并发编程的一大任务就是要调度不同计算,控制它们对资源的访问时段,以使数据竞争的情况不会发生。 此任务常称为并发同步(或者数据同步)。Go支持几种并发同步技术,这些并发同步技术将在后面的章节中逐一介绍。
并发编程中的其它任务包括:- 决定需要开启多少计算;
- 决定何时开启、阻塞、解除阻塞和结束哪些计算;
- 决定如何在不同的计算中分担工作负载。
上一节中这个并发程序是有缺陷的。我们本期望每个新创建的协程打印出10条问候语,但是主协程(和程序)在这20条问候语还未都打印出来的时候就退出了。 如何确保主协程在这20条问候语都打印完毕之后才退出呢?我们必须使用某种并发同步技术来达成这一目标。
Go支持几种并发同步技术。
其中, 通道是最独特和最常用的。
但是,为了简单起见,这里我们将使用sync标准库包中的WaitGroup来同步上面这个程序中的主协程和两个新创建的协程。
WaitGroup类型有三个方法(特殊的函数,将在以后的文章中详解):Add、Done和Wait。
此类型将在后面的某篇文章中详细解释,目前我们可以简单地认为:
-
Add方法用来注册新的需要完成的任务数。 -
Done方法用来通知某个任务已经完成了。 -
一个
Wait方法调用将阻塞(等待)到所有任务都已经完成之后才继续执行其后的语句。
package main
import (
"log"
"math/rand"
"time"
"sync"
)
var wg sync.WaitGroup
func SayGreetings(greeting string, times int) {
for i := 0; i < times; i++ {
log.Println(greeting)
d := time.Second * time.Duration(rand.Intn(5)) / 2
time.Sleep(d)
}
wg.Done() // 通知当前任务已经完成。
}
func main() {
rand.Seed(time.Now().UnixNano()) // Go 1.20之前需要
log.SetFlags(0)
wg.Add(2) // 注册两个新任务。
go SayGreetings("hi!", 10)
go SayGreetings("hello!", 10)
wg.Wait() // 阻塞在这里,直到所有任务都已完成。
}
运行这个修改后的程序,我们将会发现所有的20条问候语都将在程序退出之前打印出来。
协程的状态
从上面这个的例子,我们可以看到一个活动中的协程可以处于两个状态:运行状态和阻塞状态。一个协程可以在这两个状态之间切换。
比如上例中的主协程在调用wg.Wait方法的时候,将从运行状态切换到阻塞状态;当两个新协程完成各自的任务后,主协程将从阻塞状态切换回运行状态。
下面的图片显示了一个协程的生命周期。
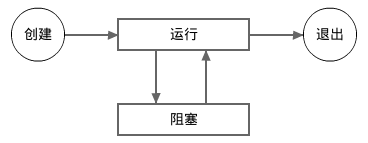
注意,一个处于睡眠中的(通过调用time.Sleep)或者在等待系统调用返回的协程被认为是处于运行状态,而不是阻塞状态。
当一个新协程被创建的时候,它将自动进入运行状态,一个协程只能从运行状态而不能从阻塞状态退出。 如果因为某种原因而导致某个协程一直处于阻塞状态,则此协程将永远不会退出。 除了极个别的应用场景,在编程时我们应该尽量避免出现这样的情形。
一个处于阻塞状态的协程不会自发结束阻塞状态,它必须被另外一个协程通过某种并发同步方法来被动地结束阻塞状态。 如果一个运行中的程序当前所有的协程都出于阻塞状态,则这些协程将永远阻塞下去,程序将被视为死锁了。 当一个程序死锁后,官方标准编译器的处理是让这个程序崩溃。
比如下面这个程序将在运行两秒钟后崩溃。package main
import (
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
wg.Add(1)
go func() {
time.Sleep(time.Second * 2)
wg.Wait() // 阻塞在此
}()
wg.Wait() // 阻塞在此
}
fatal error: all goroutines are asleep - deadlock!
...
以后我们将学习到更多可以让一个协程进入到阻塞状态的操作。
协程的调度
并非所有处于运行状态的协程都在执行。在任一时刻,只能最多有和逻辑CPU数目一样多的协程在同时执行。
我们可以调用runtime.NumCPU函数来查询当前程序可利用的逻辑CPU数目。
每个逻辑CPU在同一时刻只能最多执行一个协程。Go运行时(runtime)必须让逻辑CPU频繁地在不同的处于运行状态的协程之间切换,从而每个处于运行状态的协程都有机会得到执行。
这和操作系统执行系统线程的原理是一样的。
下面这张图显示了一个协程的更详细的生命周期。在此图中,运行状态被细分成了多个子状态。 一个处于排队子状态的协程等待着进入执行子状态。一个处于执行子状态的协程在被执行一会儿(非常短的时间片)之后将进入排队子状态。
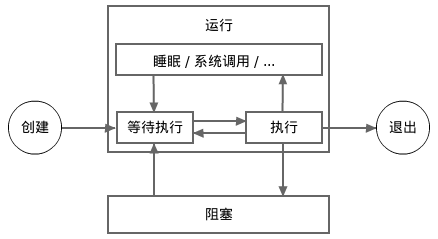
请注意,为了解释的简单性,在以后其它的《Go语言101》文章中,上图中所示的子状态将不会再提及。 重申一下,睡眠和等待系统调用返回子状态被认为是运行状态,而不是阻塞状态。
标准编译器采纳了一种被称为M-P-G模型的算法来实现协程调度。 其中,M表示系统线程,P表示逻辑处理器(并非上述的逻辑CPU),G表示协程。 大多数的调度工作是通过逻辑处理器(P)来完成的。 逻辑处理器像一个监工一样通过将不同的处于运行状态协程(G)交给不同的系统线程(M)来执行。 一个协程在同一时刻只能在一个系统线程中执行。一个执行中的协程运行片刻后将自发地脱离让出一个系统线程,从而使得其它处于等待子状态的协程得到执行机会。
在运行时刻,我们可以调用runtime.GOMAXPROCS函数来获取和设置逻辑处理器的数量。
我们也可以通过设置GOMAXPROCS环境变量来设置一个Go程序的初始逻辑处理器数量。
延迟函数调用(deferred function call)
在Go中,一个函数调用可以跟在一个defer关键字后面,成为一个延迟函数调用。
此defer关键字和此延迟函数调用一起形成一个延迟调用语句。
和协程调用类似,被延迟的函数调用的所有返回值(如果存在)必须全部被舍弃。
当一个延迟调用语句被执行时,其中的延迟函数调用不会立即被执行,而是被推入由调用此延迟语句的函数调用维护的一个延迟调用栈。
当一个函数调用(这里称作fc)返回(此时可能尚未完全退出)并进入它的退出阶段后,所有已经被推入此函数调用所维护的延迟调用栈中的延迟函数调用被按照它们被推入的顺序逆序被移出延迟调用栈并执行。
当所有这些延迟调用执行完毕后,此函数调用(fc)也就完全退出了。
package main
import "fmt"
func main() {
defer fmt.Println("The third line.")
defer fmt.Println("The second line.")
fmt.Println("The first line.")
}
The first line.
The second line.
The third line.
下面是另一个略微复杂一点的使用了延迟调用的例子程序。此程序将按照自然数的顺序打印出0到9十个数字。
package main
import "fmt"
func main() {
defer fmt.Println("9")
fmt.Println("0")
defer fmt.Println("8")
fmt.Println("1")
if false {
defer fmt.Println("not reachable")
}
defer func() {
defer fmt.Println("7")
fmt.Println("3")
defer func() {
fmt.Println("5")
fmt.Println("6")
}()
fmt.Println("4")
}()
fmt.Println("2")
return
defer fmt.Println("not reachable")
}
一个延迟调用可以修改包含此延迟调用的最内层函数的返回值
package main
import "fmt"
func Triple(n int) (r int) {
defer func() {
r += n // 修改返回值
}()
return n + n // <=> r = n + n; return
}
func main() {
fmt.Println(Triple(5)) // 15
}
延迟函数调用的必要性和好处
事实上,上面的几个使用了延迟函数调用的例子中的延迟函数调用并非绝对必要。 但是延迟调用对于下面将要介绍的恐慌/恢复特性是必要的。
另外延迟函数调用可以帮助我们写出更整洁和更鲁棒的代码。我们可以在后面的更多关于延迟调用一文中读到这样的例子。
协程和延迟调用的实参的估值时刻
一个延迟调用的实参是在此调用对应的延迟调用语句被执行时被估值的。 或者说,它们是在此延迟调用被推入延迟调用栈时被估值的。 这些被估值的结果将在以后此延迟调用被执行的时候使用。
一个匿名函数体内的表达式是在此函数被执行的时候才会被逐渐估值的,不管此函数是被普通调用还是延迟/协程调用。
一个例子:// eval-moment.go
package main
import "fmt"
func main() {
func() {
var x = 0
for i := 0; i < 3; i++ {
defer fmt.Println("a:", i + x)
}
x = 10
}()
fmt.Println()
func() {
var x = 0
for i := 0; i < 3; i++ {
defer func() {
fmt.Println("b:", i + x)
}()
}
x = 10
}()
}
$ gotv 1.21. run eval-moment.go
[Run]: $HOME/.cache/gotv/tag_go1.21.8/bin/go run eval-moment.go
a: 2
a: 1
a: 0
b: 13
b: 13
b: 13
$ gotv 1.22. run eval-moment.go
[Run]: $HOME/.cache/gotv/tag_go1.22.1/bin/go run eval-moment.go
a: 2
a: 1
a: 0
b: 12
b: 11
b: 10
请注意Go 1.22对for循环流程控制做出的语义修改而导致的代码行为变化。
for i := 0; i < 3; i++ {
defer func(i int) {
// 此i为形参i,非实参循环变量i。
fmt.Println("b:", i)
}(i)
}
for i := 0; i < 3; i++ {
i := i // 在下面的调用中,左i遮挡了右i。
// <=> var i = i
defer func() {
// 此i为上面的左i,非循环变量i。
fmt.Println("b:", i)
}()
}
同样的估值时刻规则也适用于协程调用。下面这个例子程序将打印出
123 789。
package main
import "fmt"
import "time"
func main() {
var a = 123
go func(x int) {
time.Sleep(time.Second)
fmt.Println(x, a) // 123 789
}(a)
a = 789
time.Sleep(2 * time.Second)
}
顺便说一句,使用time.Sleep调用来做并发同步不是一个好的方法。
如果上面这个程序运行在一个满负荷运行的电脑上,此程序可能在新启动的协程可能还未得到执行机会的时候就已经退出了。
在正式的项目中,我们应该使用并发同步技术一文中列出的方法来实现并发同步。
恐慌(panic)和恢复(recover)
Go不支持异常抛出和捕获,而是推荐使用返回值显式返回错误。 不过,Go支持一套和异常抛出/捕获类似的机制。此机制称为恐慌/恢复(panic/recover)机制。
我们可以调用内置函数panic来产生一个恐慌以使当前协程进入恐慌状况。
进入恐慌状况是另一种使当前函数调用开始返回的途径。 一旦一个函数调用产生一个恐慌,此函数调用将立即进入它的退出阶段。
通过在一个延迟函数调用之中调用内置函数recover,当前协程中的一个恐慌可以被消除,从而使得当前协程重新进入正常状况。
如果一个协程在恐慌状况下退出,它将使整个程序崩溃。
内置函数panic和recover的声明原型如下:
func panic(v interface{})
func recover() interface{}
接口(interface)类型和接口值将在以后的文章接口中详解。
目前,我们可以暂时将空接口类型interface{}视为很多其它语言中的any或者Object类型。
换句话说,在一个panic函数调用中,我们可以传任何实参值。
一个recover函数的返回值为其所恢复的恐慌在产生时被一个panic函数调用所消费的参数。
package main
import "fmt"
func main() {
defer func() {
fmt.Println("正常退出")
}()
fmt.Println("嗨!")
defer func() {
v := recover()
fmt.Println("恐慌被恢复了:", v)
}()
panic("拜拜!") // 产生一个恐慌
fmt.Println("执行不到这里")
}
嗨!
恐慌被恢复了: 拜拜!
正常退出
下面的例子在一个新协程里面产生了一个恐慌,并且此协程在恐慌状况下退出,所以整个程序崩溃了。
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("hi!")
go func() {
time.Sleep(time.Second)
panic(123)
}()
for {
time.Sleep(time.Second)
}
}
hi!
panic: 123
goroutine 5 [running]:
...
Go运行时(runtime)会在若干情形下产生恐慌,比如一个整数被0除的时候。下面这个程序将崩溃退出。
package main
func main() {
a, b := 1, 0
_ = a/b
}
panic: runtime error: integer divide by zero
goroutine 1 [running]:
...
一般说来,恐慌用来表示正常情况下不应该发生的逻辑错误。 如果这样的一个错误在运行时刻发生了,则它肯定是由于某个bug引起的。 另一方面,非逻辑错误是现实中难以避免的错误,它们不应该导致恐慌。 我们必须正确地对待和处理非逻辑错误。
更多可能由Go运行时产生的恐慌将在以后其它文章中提及。
以后,我们可以了解一些恐慌/恢复用例和更多关于恐慌/恢复机制的细节。
一些致命性错误不属于恐慌
对于官方标准编译器来说,很多致命性错误(比如栈溢出和内存不足)不能被恢复。它们一旦产生,程序将崩溃。
Go101.org网站内容包括Go编程各种相关知识(比如Go基础、Go优化、Go细节、Go实战、Go测验、Go工具等)。后续将不断有新的内容加入。敬请收藏关注期待。
本丛书微信公众号(联系方式一)名称为"Go 101"。二维码在网站首页。此公众号将时不时地发表一些Go语言相关的原创短文。各位如果感兴趣,可以搜索关注一下。
《Go语言101》系列丛书项目目前托管在Github上(联系方式二)。欢迎各位在此项目中通过提交bug和PR的方式来改进完善《Go语言101》丛书中的各篇文章。我们可以在项目目录下运行go run .来浏览和确认各种改动。
本书的twitter帐号为@Golang_101(联系方式三)。玩推的Go友可以适当关注。
你或许对本书作者老貘开发的一些App感兴趣。

(《Go语言101》系列丛书由老貘从2016年7月开始编写。目前此系列丛书仍在不断改进和增容中。你的赞赏是本系列丛书和此Go101.org网站不断增容和维护的动力。)
目录:
- 关于《Go语言101》 - 为什么写这本书
- 致谢
-
Go编程入门
- 程序源代码基本元素介绍
- 关键字和标识符
- 基本类型和它们的字面量表示
- 常量和变量 - 顺便介绍了类型不确定值和类型推断
- 运算操作符 - 顺便介绍了更多的类型推断规则
- 函数声明和调用
- 代码包和包引入
- 表达式、语句和简单语句
- 基本流程控制语法
- 协程、延迟函数调用、以及恐慌和恢复
- Go类型系统
-
一些专题
- 代码断行规则
- 更多关于延迟函数调用的知识点
- 一些恐慌/恢复用例
- 详解panic/recover原理 - 也解释了什么是“函数退出阶段”
- 代码块和标识符作用域
- 表达式估值顺序规则
- 值复制成本
- 边界检查消除
-
并发编程
- 并发同步概述
- 通道用例大全
- 如何优雅地关闭通道
- 其它并发同步技术 - 如何使用
sync标准库包 - 原子操作 - 如何使用
sync/atomic标准库包 - Go中的内存顺序保证
- 一些常见并发编程错误
- 内存相关